
####一个网络爬虫工具包
webmagic的发起源于工作中的需要,其定位是帮助开发者更便捷的开发一个垂直的网络爬虫。
webmagic的功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),开发者可以便捷的使用xpath和正则表达式进行链接和内容的提取,只需编写少量代码即可完成一个定制爬虫。
###特色###
-
####垂直爬虫#### webmagic着重于页面抽取的工作。开发者可以使用xpath和正则表达式进行链接和内容的提取,支持链式API调用,以及单复数转换。
String content = page.getHtml().xpath("//div[@class='body']").regex("这段话比较重要(.*)").toString(); -
####嵌入式&无配置#### webmagic与其他Full-Stack的框架不同,没有配置文件,大部分功能都通过简单的API调用完成。webmagic以jar包的形式存在,并且不依赖任何框架,在程序可以随处进行调用。
以下是爬取oschina博客的一段代码:
Spider.create(new SimplePageProcessor("http://my.oschina.net/", "http://my.oschina.net/*/blog/*")).run(); -
####可扩展#### 参考
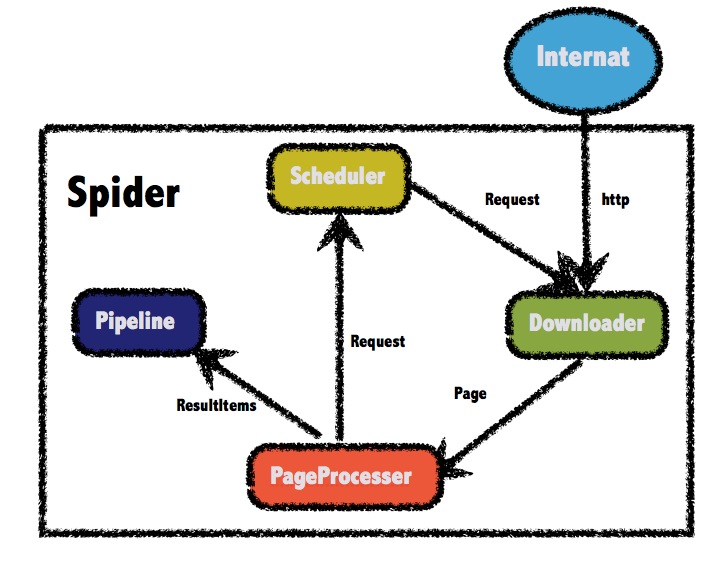
scrapy的设计,webmagic将爬虫的扩展点分为Processor、Schedular、Downloader、Pipeline三个模块,可以通过扩展这些接口实现强大的扩展功能。如可以通过多个Spider实现多线程抓取;可以通过扩展Schedular实现断点续传乃至于分布式爬虫;可以通过扩展Pipeline实现业务可定制的持久化功能。webmagic的架构原理见作者的一篇文章:webmagic的设计机制及原理-如何开发一个Java爬虫
###Get Started
webmagic定制的核心是PageProcessor接口。
项目使用maven托管,如果没用maven的可以去http://git.oschina.net/flashsword20/webmagic-bin库下载依赖包(这个仓库代码没有实时同步更新,不过依赖应该不会有变化)。
例如,我们要实现一个简单的通用爬虫SimplePageProcessor,代码如下:
public class SimplePageProcessor implements PageProcessor {
private String urlPattern;
private static final String UA = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31";
private Site site;
public SimplePageProcessor(String startUrl, String urlPattern) {
this.site = Site.me().setStartUrl(startUrl).
setDomain(UrlUtils.getDomain(startUrl)).setUserAgent(UA);
this.urlPattern = "("+urlPattern.replace(".","\\.").replace("*","[^\"'#]*")+")";
}
@Override
public void process(Page page) {
List<String> requests = page.getHtml().links().regex(urlPattern).toStrings();
//调用page.addTargetRequests()方法添加待抓取链接
page.addTargetRequests(requests);
//xpath方式抽取
page.putField("title", page.getHtml().xpath("//title"));
//sc表示使用Readability技术抽取正文
page.putField("content", page.getHtml().smartContent());
}
@Override
public Site getSite() {
//定义抽取站点的相关参数
return site;
}
}
调用这个爬虫的代码如下:
Spider.create(new SimplePageProcessor("http://my.oschina.net/", "http://my.oschina.net/*/blog/*")).run();
webmagic-samples目录里有一些定制PageProcessor以抽取不同站点的例子。
作者还有一个使用webmagic进行抽取并持久化到数据库的项目JobHunter。这个项目整合了Spring,自定义了Pipeline,使用mybatis进行数据持久化。
webmagic遵循Apache 2.0协议
webmagic的架构和设计参考了以下两个项目,感谢以下两个项目的作者:
python爬虫 scrapy https://github.com/scrapy/scrapy
Java爬虫 Spiderman https://gitcafe.com/laiweiwei/Spiderman