这个项目主要目的是对Hive所支持的存储结构进行扩展。当前Hive所支持的存储结构是textfile,sequencefile,rcfile以及最新出来的ORC。他们各自的优势在这里就不详细说明了。下面谈谈要实现的存储结构FOSF(Flexible Optimized SegmentFile)的特点。
整个工程的有效代码约21000行,涉及到的代码约数十万行。
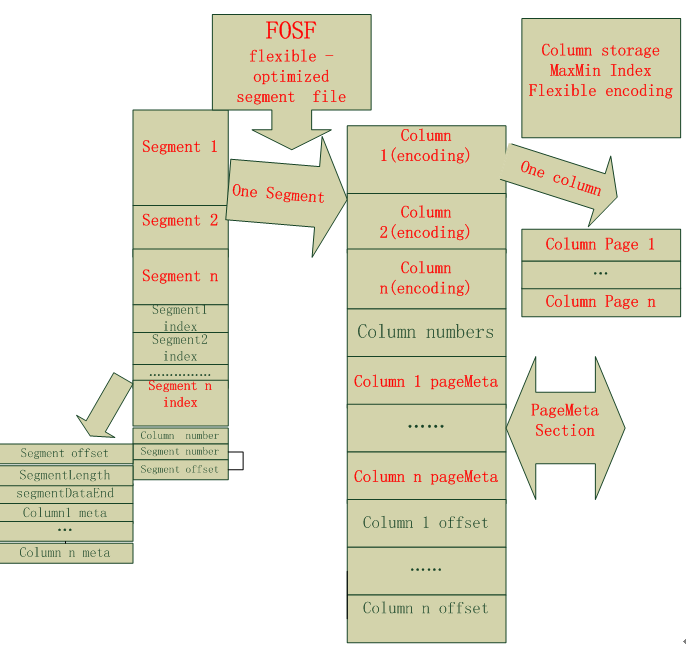
FOSF结合了行和列混合存储的方式,行存储主要是用来保证一个元组的所有属性都存储在同一个block上,这样可以大大避免查询时期元组重构所带来的跨节点的网络IO开销,而采用列存储的话,一则是对于海量数据的OLAP这种查询而言可以避免查询不相关的列加载进入内存,二是由于数据列都是同一种数据类型,这使得列存储的压缩性能非常好。需要说明的是,先前曾尝试着采用列簇存储的方式,当初的动机是让查询相关的列放在一个列簇里面,这样的话可以减少查询时候的磁盘IO开销,但是这种方式就是灵活度太差,而且对于查询涉及到多个列簇的话等情况会加载额外的数据列进入内存,而且列簇的加载和重组也是一笔不小的开销,得不偿失。鉴于此,后来就放弃了列簇的想法。
接下来,在行和列混合存储的基础上,引入了索引机制。就是为每一个列设立一个最小基本单元,基本单元可以byte size为单位,也可以记录个数为单位建立粗糙的索引,即记录这个列的最大值和最小值。请注意这是一种粗糙索引。这样的话在sql查询中会起到一定的过滤作用,可以避免查询涉及的列中无关的一部分数据加载进入内存。在当前的Hive执行流程中,如果需要利用此Index进行过滤的话,需要实现 filterPushDown机制。
紧接着,鉴于当前所采用的压缩算法大多是LZO ZLIB等重量级的压缩编码方式,为了提高压缩性能进而节省存储空间以及提高查询性能,我们决定依据每一个数据列的属性和分布情况(连续重复,重复不连续,等差数列,相邻数值增量较小,甚至非重复个数较少等)采用最适合其的编码方式,具体的编码方式有deltabitPacking, DictionaryRedBlackTree,RunLengthEncoding,googleProtoBufferVLQ等编码,核心是考虑数据类型特点以及分布情况,关键技术是位编码,增量编码,字典编码,VLQ等,编码部分参考了twitter开源的产品 ,但是其算法是和其程序耦合在一起的,耦合度较高,需要开发者自己花功夫从其中提取,并在现有编码基础上组合出更加高效的编码方式。 部分参考http://lemire.me/blog/archives/2012/03/06/how-fast-is-bit-packing/
简而言之,FOSF的特点是 行和列混合存储+高效索引+数据统计+自适应的最优化压缩算法(deltaBitPacking Trie) +LazyLoad+牺牲精度的近似查询
那这个存储结构是如何实现到Hive里面的呢?Hive提供了一个名为storagehandel的接口用于扩展其存储结构。用户只需要实现其相关接口,便可以让其支持你的存储结构。请注意,是支持基本功能,后来发现选择storageHandel来扩展存储结构有点坑。 FOSF性能如何?
在实现了上述功能之后,做了一个较为详细的性能测试,不管是从编码时间,解码时间,压缩比 以及sql查询时间来看都有较为明显的性能提升,github好像上不了PDF,就不方便和大家分享了。
1.假设我们的segment的大小和hdfs block的size都是256M,可是事实上由于存储结构自身的特性,我们不能保证一个完整的segment size恰好是256M,由此带来的问题是有可能一个segment的meata data元数据信息和其代表的数据内容(约256M)存储在不同的block甚至是不同的node上面,这样会带来一定网络开销。对此想到的一个方法是让一个segment 的实际size是能存储完整元组的小于256M的最大值,然后空缺剩余的一小部分空间,经接着开启一个新的block写下一个segment.
2.在加载生成FOSF格式的数据的时候,是会有多个map任务同时进行,这是就涉及到为每一个生成小文件去名字的问题。在分布式环境下要保证名字的唯一,这时候可以调用hdfs的一个方法来获取map task的唯一编号以依据此编码来命名。
3.在代码层次上,采用arraylist来存储每一列的byte值,考虑到arraylist在resize时候的开销,如何确定初始值还是比较关键的,另外,比如说java函数指针等方式的使用也可以提升一定的性能,当然,用一个性能测试工具比如说netbeans还是很有帮助的。
1.由于采用storageHandel接口来扩展FOSF,这就导致了很多问题,第一不支持小文件合并,这就直接导致我们在小文件较小的时候,map任务数过多而导致大大增加任务启动时间和查询时间。所以只能开发者实现小文件合并,其他 还有诸多查询方式居然也不能支持比如count(1),只能开发者自己改,表示头都大了。
2.耦合性和sqllite考虑到Apache Hive社区版本更新很快,为了能让Hive支持FOSF扩展结构,尽量采用松耦合的方式,所以绝大多数代码(约20000行)全部是在存储结构自己的逻辑中实现中,涉及到修改Hive源码的地方比较少,榆次同时采用一个轻量级数据库sqllite用于存放和FOSF存储结构相关的表信息的元数据信息,也是为何和Hive支持的数据库保持一定的松耦合性。
3.前面提到,存储结构中使用了记录一个基本粒度的MaxMin用于在查询时候过滤掉一些无关的数据,这种索引技术是很粗糙的,在后来的性能测试中发现效果不太理想(当然,排序情况下会好很多,但不符合实际情况),简单一点就是说不少情况下where id>vlaue 这个value值不能决定一个小的page是全部满足此条件还是全部不满足,更多情况下是这个基本粒度page中的value一部分满足一部分不满足,这样的话其实就是IndexFilter没有起到过滤作用,需要逐行进行暴力比较。索引Index优化的核心就是减少这种暴力比较的情况的出现 。一个方法就是减小简建立Index的基本粒度,这样的话虽然能过滤掉更多无关的数据,但是建立更多的Index会增大存储空间和查询时候的计算代价。所以索引技术这一块,在混合存储的基础上确实没想到更优化的方法,行存储的细粒度的索引机制好像不太适合这种场景。
4.在实现压缩算法的过程中,借鉴了googleProtoBuffer里面的VLQ算法(http://code.google.com/p/protobuf/), 但是大家都知道Protobuffer更大的价值还在于其对结构化数据进行序列化存储的高效和简单,除了其紧凑的编码算法外,希望可以把protobuffer的序列化方式用在现有的FOSF存储结构上面。
5.当前为每一个列选择一个编码算法是在创建表的时候定义的,问题是如果用户不知道表的数据列的分布情况,那么为其选择编码方式就是个问题。当前解决方案是为其使用一般情况下性能较好的增量位编码。后期规划是希望在数据进行加载的时候统计数据的分布情况动态的选择最适编码压缩方式。 6.当前的存储结构只能支持基本的数据类型,还不能支持MAP,LIST等复杂数据类型,不过有了一定的解决思路。 HDFS_WriteBug等诸多bug
https://issues.apache.org/jira/browse/HDFS-5996 在此存储结构的实现过程中,遇到了较多的bug。影响最深的就是HDFS-Write的bug,不管充hadoop counters还是自己打印的多种记录信息,都没发现问题,全程无任何异常,最后是通过吧map结果先写到新建的临时文件,然后再move到/user、hive/warehouse/ 最终存储目录下面,方才搞定。其他问题,比如说序列化问题,变长字符串编码压缩问题行缺失问题,Index 做记录的Max和Min和实际情况不符合等 开发以及运行环境
主要用java语言开发,也用到了shell(自动化加载),python(轻量级sqllite数据库,这得谢谢朋友的帮忙)。。。。如果要使用此存储结构的话,需要有hadoop和Hive的环境以及sqllite数据库,这样你就可以像使用Hive一样来使用这个存储结构了。
如果你仅仅想把其他数据类型存储为FOSF存储格式的话,你可以写一个mapreduce job来实现这个简单的ETL操作。我也试过,遗憾的是此job是有reduce任务的,而大家都知道Hive的加载机制只有map任务没有reduce任务。所以性能上差距明显。
希望在把当下的工作做完之后可以对spark和shark有较为深入的理解,也希望自己在分布式系统,流处理,实时处理,离线处理,数据挖掘,图计算领域能够走的更远。